# ruoyi-cloud-hbase
**Repository Path**: avatarwx/ruoyi-cloud-hbase
## Basic Information
- **Project Name**: ruoyi-cloud-hbase
- **Description**: TB级大数据平台,基于RuoYi-cloud + hadoop + hbase + phonenix的若依微服务后台管理系统,使用hbase引擎替代传统关系数据库mysql,重写若依systen模块,保留若依系统原有功能。
- **Primary Language**: Unknown
- **License**: MIT
- **Default Branch**: master
- **Homepage**: https://s4.s100.vip:14280
- **GVP Project**: No
## Statistics
- **Stars**: 19
- **Forks**: 11
- **Created**: 2024-05-20
- **Last Updated**: 2025-08-14
## Categories & Tags
**Categories**: Uncategorized
**Tags**: ruoyi-hadoop, ruoyi-hbase, phoenix, ruoyi-cloud-hbase, hbase
## README
## 平台简介
- 基于RuoYi-cloud3.6.3 + hadoop-3.2.0 + hbase-2.2.7 + phonenix2.2的若依后台管理平台,TB级大数据平台,使用hbase引擎替代传统关系数据库mysql,重写若依systen模块,保留若依系统原有功能。
- 记得右上角点个 star 持续关注更新哟~~

## 系统模块
```
com.ruoyi
├── ruoyi-ui // 前端框架 [14280]
├── ruoyi-gateway // 网关模块 [13502]
├── ruoyi-auth // 认证中心 [12331]
├── ruoyi-api // 接口模块
│ └── ruoyi-api-system // 系统接口
├── ruoyi-common // 通用模块
│ └── ruoyi-common-core // 核心模块
......
├── ruoyi-modules // 业务模块
│ └── ruoyi-hbase // 系统模块 [23040]
│ └── ruoyi-gen // 代码生成 [34017]
│ └── ruoyi-job // 定时任务 [38558]
│ └── ruoyi-file // 文件服务 [12493]
├── ruoyi-visual // 图形化管理模块
│ └── ruoyi-visual-monitor // 监控中心 [9100]
├──pom.xml // 公共依赖
```
## 内置功能
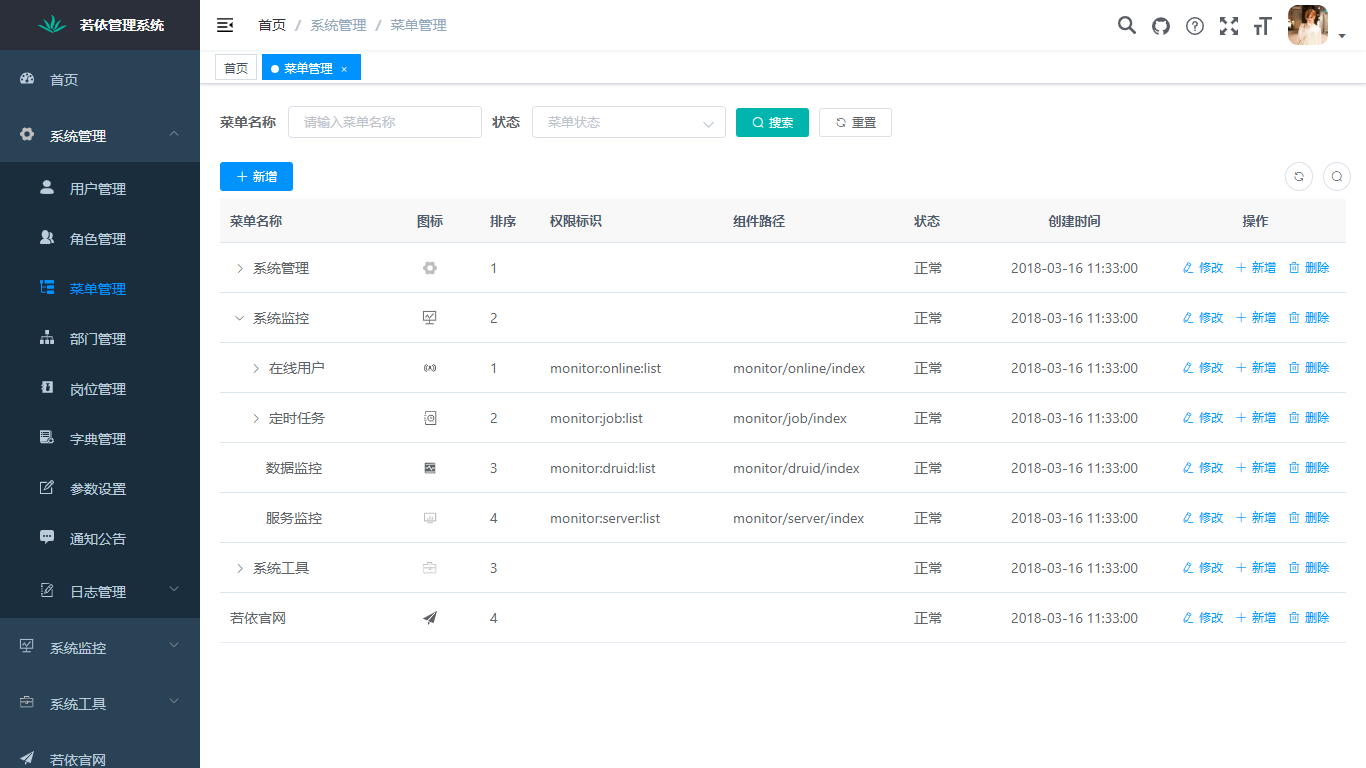
1. 用户管理:用户是系统操作者,该功能主要完成系统用户配置。
2. 部门管理:配置系统组织机构(公司、部门、小组),树结构展现支持数据权限。
3. 岗位管理:配置系统用户所属担任职务。
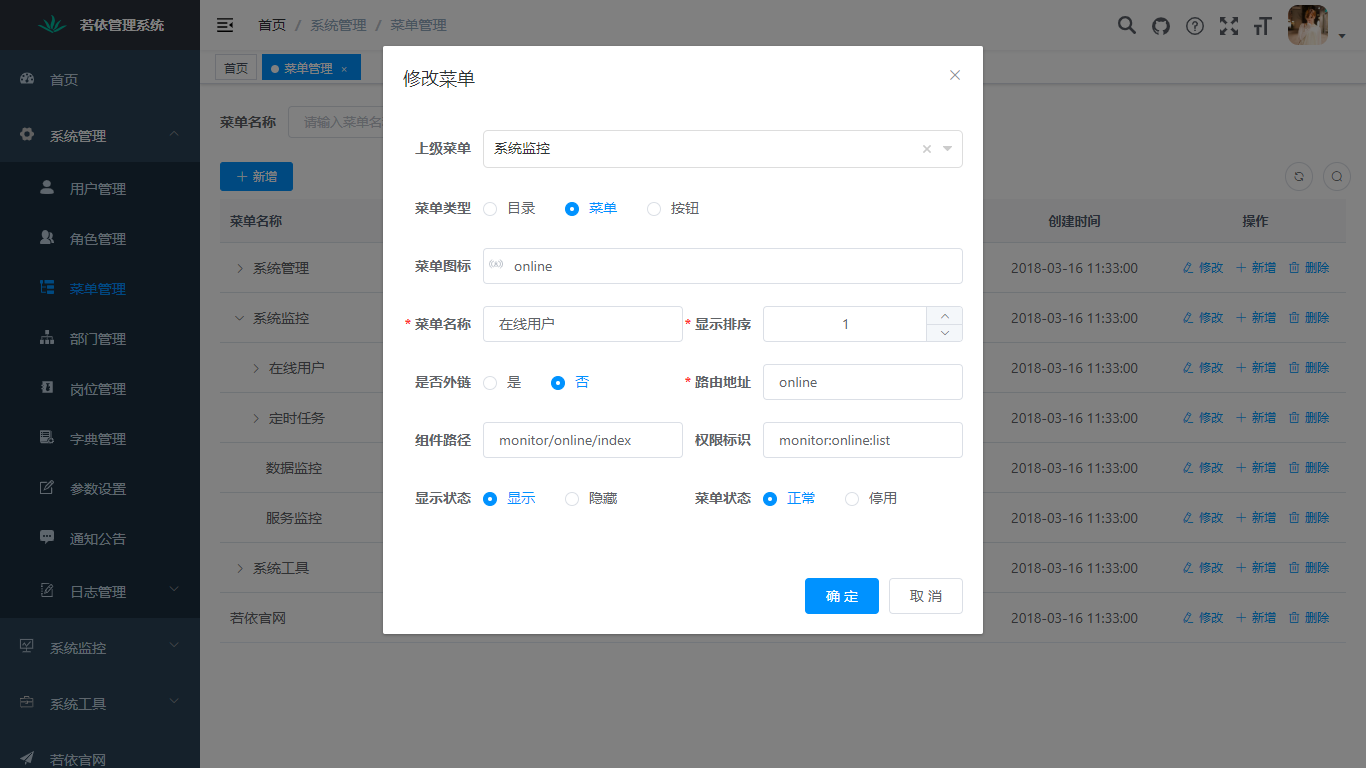
4. 菜单管理:配置系统菜单,操作权限,按钮权限标识等。
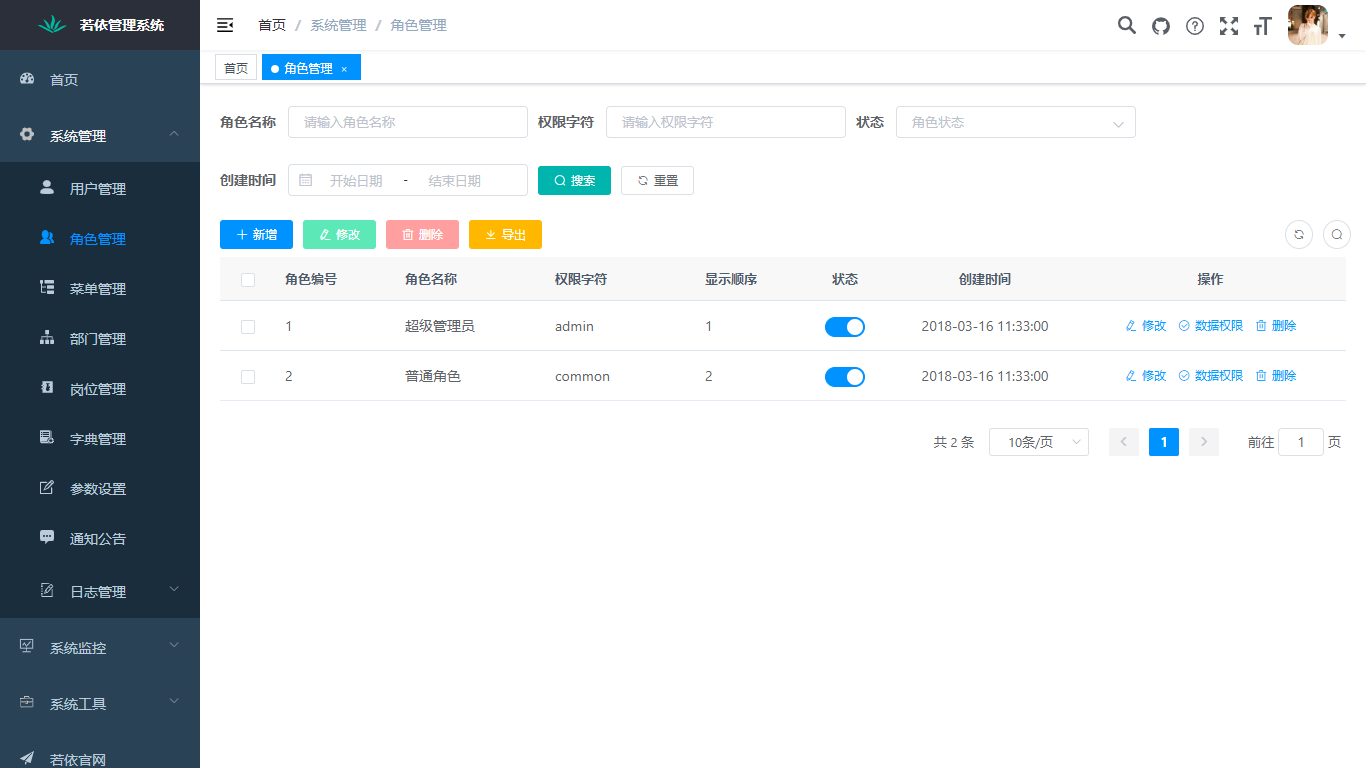
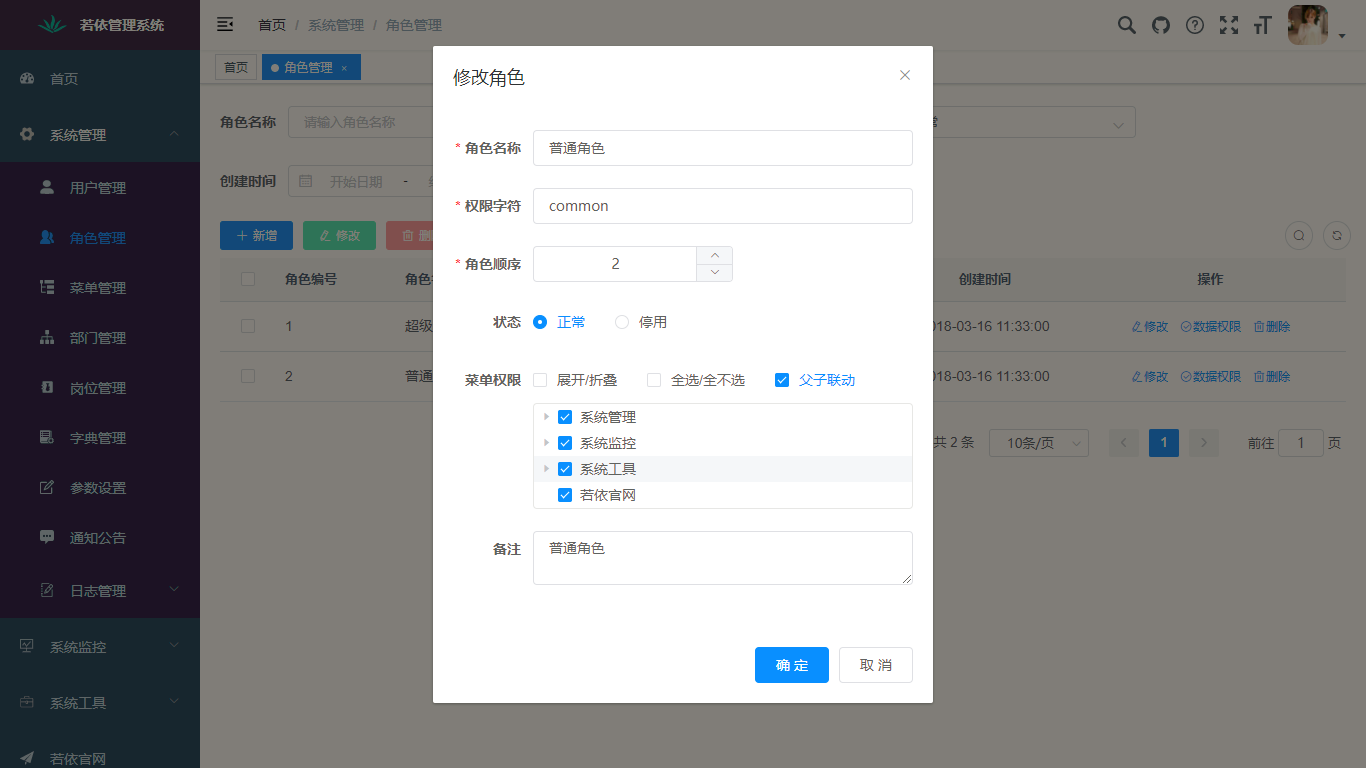
5. 角色管理:角色菜单权限分配、设置角色按机构进行数据范围权限划分。
6. 代码生成:前后端代码的生成(java、html、xml、sql)支持CRUD下载
......
## 在线体验
- (后台管理)- https://s4.s100.vip:14280
- 测试账号:admin / admin123
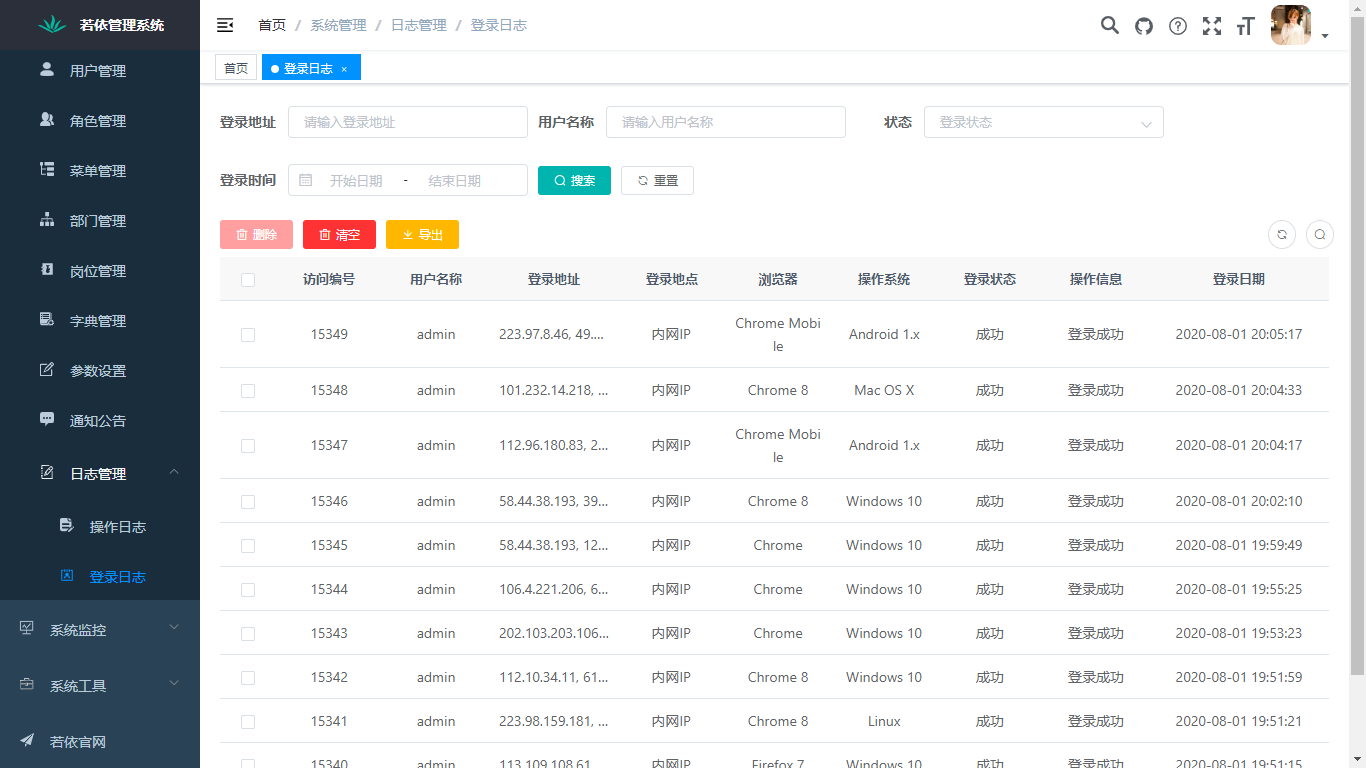
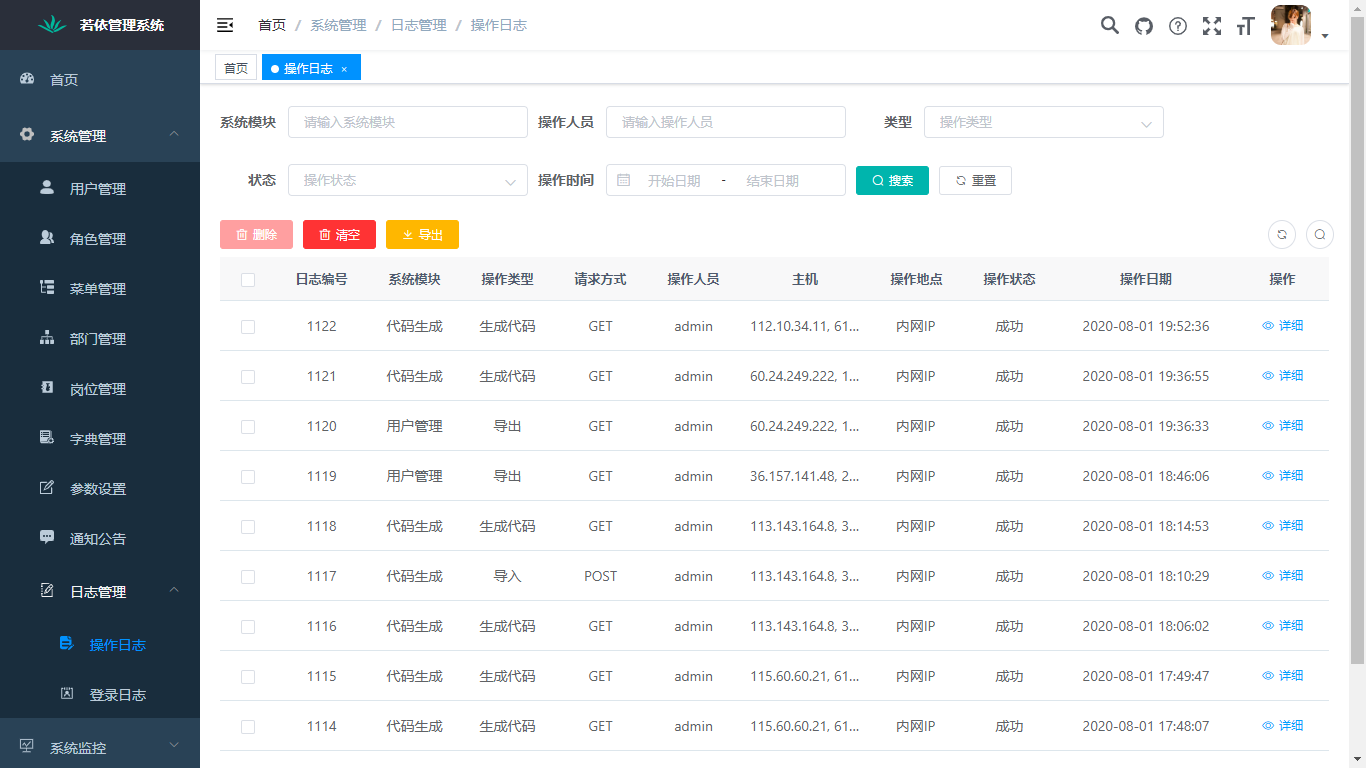
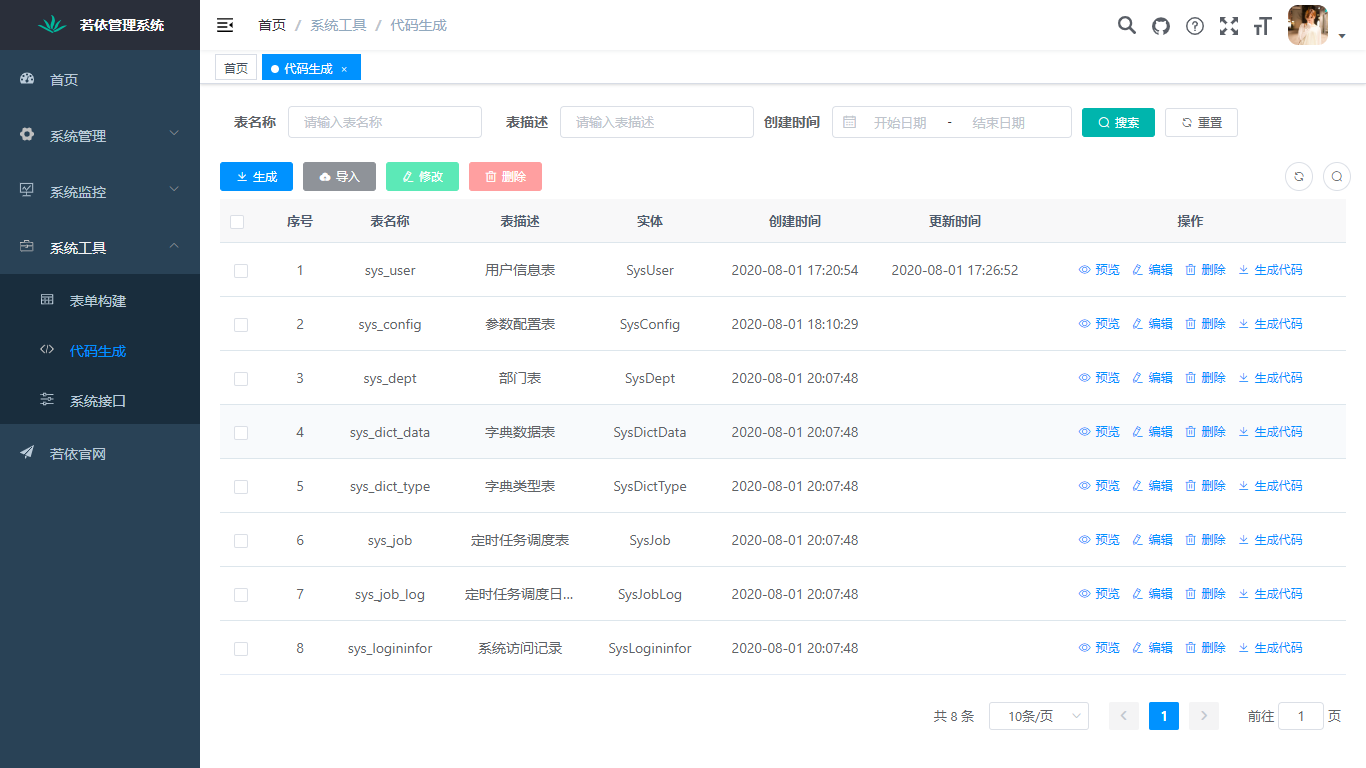
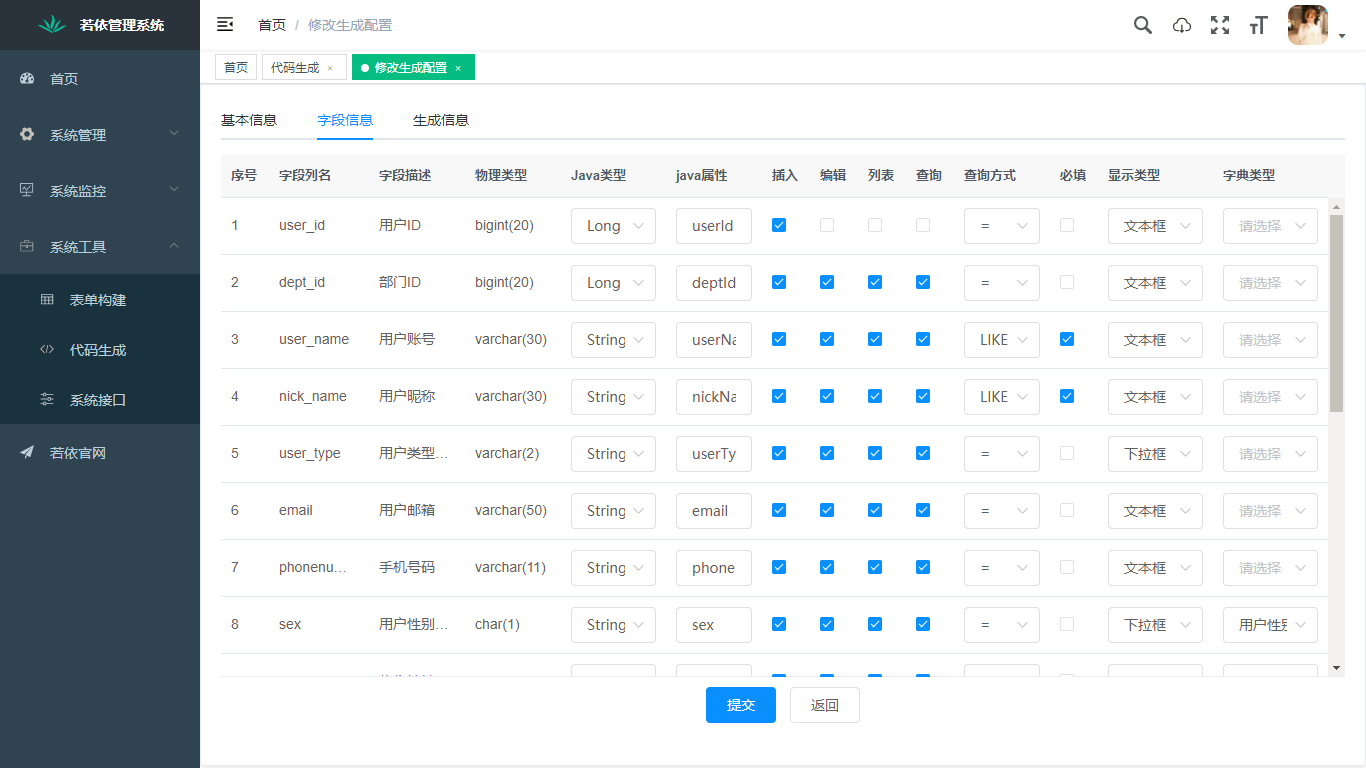
## 页面功能展示
## QQ交流群
- QQ交流群:925522426(加群请先star项目 不然验证不通过 备注格式:gitee用户名)
- 
- 点击链接加入群聊【ruoyi-cloud-hadoop交流群】:点击链接加入群聊【ruoyi-cloud-hadoop交流群】:http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=gzsuzmFB1EpOC5PTNZXuRKV8_AUwTTT7&authKey=Qdkcdnn3RDZjIRGzvNSSiCuaRu%2BxWR6W03fDpEAImgATYeVUe9A%2FRx1vyj7Wz16z&noverify=0&group_code=925522426
## 启动说明
需要对以下模块进行启动 启动顺序随意
- RuoYiAuthApplication
- RuoYiHbaseApplication(等价于启动RuoYiSystemApplication)
- RuoYiGatewayApplication
- ...
## 友情链接
- 感谢若依大佬开源的微服务项目:https://gitee.com/y_project/RuoYi-Cloud
## 插件版本
- RuoYi-Cloud 3.6.3
- Nacos 2.0.2
- jdk1.8.0_281
- hadoop-3.2.0
- zookeeper-3.5.8
- hbase-2.2.7
- phonenix2.2
- Node.js 14.0.0
- npm 6.14.4
- 操作系统使用Linux内核的centos7.6 或者centos7.9系统作为搭建环境最稳定(亲测) AlmaLinux 8也可以(但是安装hue会失败)
## 痛点解决
- 平时我们在开发程序时,最常用的数据库是MySQL。但是当MySQL单表数据量超过2000万时,CRUD操作的性能会急剧下降。需要安排DBA定期将几个月的数据迁移到归档数据库中,以达到减少表数据的目的。如果你开发的是业务数据量不大的MIS系统,MySQL也能应对。但对于像电商平台或AI平台这样每天产生大量业务数据的项目来说,一两个月就能积累数千万条数据。选择一个能够容纳数百TB数据且无需归档的大数据平台。这不仅可以降低开发难度,还能减少DBA的运维成本。
- ruoyi-cloud-habse就是这样的快速开发平台。
## ruoyi-cloud-habse相比于传统框架的优点
#### 能装下更多数据:
- HBase:HBase就像是一个能无限扩展的大仓库,数据再多也能装得下。你可以不停地增加新的存储单元来放更多的数据。
- MySQL:MySQL就像一个固定大小的仓库,装满了就不太好扩展了,虽然也有办法加一些新的单元,但操作起来没那么方便。
#### 读写速度快:
- HBase:HBase读写数据很快,特别是写入数据的时候,能处理大量数据的同时还保持高速度。
- MySQL:MySQL在数据量很大的时候,读写速度可能会变慢,特别是当很多人同时读写的时候。
#### 处理大数据很厉害:
- HBase:HBase天生就是为处理海量数据设计的,哪怕数据多到像海一样,也能轻松应对。
- MySQL:MySQL更适合处理中小规模的数据量,大数据量的时候会显得有些吃力。
#### 灵活存储各种数据:
- HBase:HBase对存储的数据类型不挑剔,结构化、半结构化、非结构化的数据都能存,而且不需要预先定义好结构。
- MySQL:MySQL需要你提前设计好数据的结构(比如表和字段),之后存储的数据就得按照这个结构来,不够灵活。
#### 容易扩展:
- HBase:HBase扩展起来很方便,需要更多存储空间时,直接增加新的节点就行了,就像加新的货架一样简单。
- MySQL:MySQL扩展起来相对麻烦些,需要用一些复杂的技术手段,而且扩展效果不如HBase自然。
#### 适合高并发场景:
- HBase:HBase特别适合那种需要同时处理很多读写请求的场景,比如大型电商网站的数据后台。
MySQL:MySQL在高并发场景下可能会遇到性能瓶颈,处理不过来那么多请求。
简单来说,HBase就像一个超级大仓库,能装得下更多的数据,读写速度快,扩展灵活,特别适合那些数据量巨大、
读写频繁的场景;而MySQL则更适合中小规模、需要严格数据结构和一致性的场景。
## 接口文档及调试
* 为了方遍大家调试 楼主已经整理出了流程定义审批查看主要的接口
调试使用postman进行,打开postman,点击导入,选择ruoyi-cloud-hbase.postman_collection.json文件
即可
* 详细操作见
* https://gitee.com/avatarwx/ruoyi-cloud-hbase/wikis/ruoyi-cloud-hbase.postman_collection.json?sort_id=10961262
## 常见问题及报错解决
* 常见问题及报错解决见
* https://gitee.com/avatarwx/ruoyi-cloud-hbase/wikis/Home
## 环境安装
### 1.1 centos7.9环境初始化
#### 1.修改主机名 我这里用bigdata01
```
vi /etc/hostname
bigdata01
```
#### 2.配置主机域名
```
vi /etc/hosts
bigdata01 192.168.2.28
```
#### 3.配置网络 (其中UUID和DEVICE要保留自己的)
```
vim /etc/sysconfig/network-scripts/ifcfg-enp3s0
```
(文件内容详见::https://gitee.com/avatarwx/ruoyi-cloud-hbase.wiki.git)
```
service network retart
```
如果可以ping百度ping通 则网络没有问题
```
ping www.baidu.com
```
#### 4.关闭防火墙
```
systemctl stop firewalld
systemctl status firewalld
systemctl disable firewalld
```
#### 5.配置无密码SSH通信
确保目标服务器的sshd服务正在运行
```
systemctl status sshd
vim /etc/ssh/sshd_config
PubkeyAuthentication yes
systemctl restart sshd
```
生成SSH密钥对
```
ssh-keygen -t rsa
ll ~/.ssh
cat ~/.ssh/id_rsa.pub
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh bigdata01
```
运行ssh bigdata01就不需要输入密码则配置ssh成功
#### 6.关闭 SELinux
```
vim /etc/selinux/config
```
找到以下行:
```
SELINUX=enforcing
```
将其改为:
```
SELINUX=disabled
```
### 1.2 安装JDK
oracle官网下载jdk-8u281-linux-x64.tar.gz(加QQ群提供下载包)
上传jdk-8u281-linux-x64.tar.gz到/opt/modules目录
#### 1.创建安装目录和软件包目录
```
mkdir -p /opt/modules
mkdir -p /opt/softwares/
```
#### 2.解压
```
tar -zxvf /opt/softwares/jdk-8u281-linux-x64.tar.gz -C /opt/modules
```
#### 3.配置环境变量
```
vim /etc/profile
export JAVA_HOME=/opt/modules/jdk1.8.0_281
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
```
### 1.3 安装Hadoop
#### 1.创建安装目录和软件包目录
```
mkdir -p /opt/modules
mkdir -p /opt/softwares/
```
官网下载hadoop-3.2.0.tar.gz(也加QQ群获取下载包)
上传hadoop-3.2.0.tar.gz到/opt/modules目录
#### 2.解压
```
tar -zxvf /opt/softwares/hadoop-3.2.0.tar.gz -C /opt/modules
```
#### 3.修改/opt/modules/hadoop-3.2.0/etc/hadoop目录下的5个文件
(文件内容详见::https://gitee.com/avatarwx/ruoyi-cloud-hbase.wiki.git)
```
core-site.xml
hdfs-site.xml
mapred-site.xml
workers
yarn-site.xml
```
#### 4.修改下面4个启动脚本的权限
start-dfs.sh
start-yarn.sh
stop-dfs.sh
stop-yarn.sh
具体修改内容如下
start-dfs.sh
```
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
```
start-yarn.sh
```
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
```
stop-dfs.sh
```
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
```
stop-yarn.sh
```
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
```
#### 5.修改hadoop-env.sh文件,在末尾加入下面配置
```
export JAVA_HOME=/opt/modules/jdk1.8.0_281
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
```
#### 6.配置环境变量
```
vim /etc/profile
export HADOOP_HOME=/opt/modules/hadoop-3.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
```
#### 7.格式化集群
```
cd /opt/modules/hadoop-3.2.0
/opt/modules/hadoop-3.2.0/bin/hdfs namenode -format
```
#### 8.启动hadoop集群
```
/opt/modules/hadoop-3.2.0/sbin/start-all.sh
```
#### 启动失败报错或者格式化失败后,请执行下面这句脚本后再重新格式化和启动
```
rm -rf /data/hadoop_repo/
#### 访问hdfs和yarn的前端页面
hdfs web :http://192.168.2.28:9870/dfshealth.html#tab-overview
yarn web :http://192.168.2.28:8088/cluster
```
#### 查看日志,在该目录下查找
```
/data/hadoop_repo/logs/hadoop
```
#### 关闭集群
```
/opt/modules/hadoop-3.2.0/sbin/stop-all.sh
```
### 1.4 安装zookeeper
#### 1.解压
```
tar -zxvf /opt/softwares/apache-zookeeper-3.5.8-bin.tar.gz -C /opt/modules
```
#### 2.修改配置
```
cd /opt/modules/apache-zookeeper-3.5.8-bin/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
dataDir=/data/soft/zookeeper/data
```
#### 3.启动zookeeper
```
/opt/modules/apache-zookeeper-3.5.8-bin/bin/zkServer.sh start
```
#### zookeeper测试
```
打开zookeeper客户端
/opt/modules/apache-zookeeper-3.5.8-bin/bin/zkCli.sh
ls /
创建test节点
create /test
ls /
创建test01节点 往test01节点存储一个数据 hello
create /test01/hello
get /test01
删除节点
deleteall /test01 删除节点
quit
```
继续编写中 未完待续
### 1.5 安装hbase
#### 1.解压
```
tar -zxvf /opt/softwares/hbase-2.2.7-bin.tar.gz -C /opt/modules
```
#### 2.修改下面4个文件
```
core-site.xml
hbase-env.sh
hbase-site.xml
regionservers
```
(文件内容详见::https://gitee.com/avatarwx/ruoyi-cloud-hbase.wiki.git)
#### 3.配置环境变量
```
export JAVA_HOME=/opt/modules/jdk1.8.0_281
export HADOOP_HOME=/opt/modules/hadoop-3.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
```
#### 4.启动hbase集群
hbase依赖hadoop和zookeeper,所以先要启动hadoop和zookeeper,才可以启动hbase哦
##### 先启动Hadoop集群
```
/opt/modules/hadoop-3.2.0/sbin/start-all.sh
```
##### 启动zookeeper集群
```
/opt/modules/apache-zookeeper-3.5.8-bin/bin/zkServer.sh start
```
##### 启动HBase集群
```
/opt/modules/hbase-2.2.7/bin/start-hbase.sh
```
#### 运行hbase客户端
```
/opt/modules/hbase-2.2.7/bin/hbase shell
status
```
#### 5.访问hbase前端页面
```
http://192.168.2.8:16010/master-status
```
如果停止的话,要先停HBase集群进程,再停止Zookeeper集群和Hadoop集群
```
/opt/modules/hbase-2.2.7/bin/stop-hbase.sh
/opt/modules/apache-zookeeper-3.5.8-bin/bin/zkServer.sh stop
/opt/modules/hadoop-3.2.0/sbin/stop-all.sh
```
#### 启动失败
如果hbase第一次就启动失败 请执行下面的操作后在重新启动
```
hdfs dfs -rm -r /hbase
/opt/modules/apache-zookeeper-3.5.8-bin/bin/zkCli.sh
ls /
deleteall /hbase
quit
```
### 1.6 phoenix
#### 1.解压
```
tar -zxvf /opt/softwares/phoenix-hbase-2.2-5.1.2-bin.tar.gz -C /opt/modules
```
#### 2.复制下面3个文件到 phoenix-hbase-2.2-5.1.2-bin/bin目录下
```
cp /opt/modules/hadoop-3.2.0/etc/hadoop/core-site.xml /opt/modules/phoenix-hbase-2.2-5.1.2-bin/bin
cp /opt/modules/hadoop-3.2.0/etc/hadoop/hdfs-site.xml /opt/modules/phoenix-hbase-2.2-5.1.2-bin/bin
cp /opt/modules/hbase-2.2.7/conf/hbase-site.xml /opt/modules/phoenix-hbase-2.2-5.1.2-bin/bin
```
#### 3.复制下面2个jar文件到 /hbase-2.2.7/lib目录下
```
cp /opt/modules/phoenix-hbase-2.2-5.1.2-bin/phoenix-server-hbase-2.2-5.1.2.jar /opt/modules/hbase-2.2.7/lib
cp /opt/modules/phoenix-hbase-2.2-5.1.2-bin/phoenix-pherf-5.1.2.jar /opt/modules/hbase-2.2.7/lib
```
#### 4.配置phoenix环境变量
```
vi /etc/profile
export PHOENIX_HOME=/opt/modules/phoenix-hbase-2.2-5.1.2-bin
export PATH=$PATH:$JAVA_HOME/bin:HADOOP_HOME/bin:HADOOP_HOME/sbin:HBASE_HOME/bin:ZOOKEEPER_HOME/bin:PHOENIX_HOME/bin
source /etc/profile
```
#### 5.启动phoenix
```
/opt/modules/phoenix-hbase-2.2-5.1.2-bin/bin/sqlline.py 192.168.2.8:2181
```
### 1.7 连接phoenix 导入表结构和初始化数据
#### 1.连接phoenix客户端
```
/opt/modules/phoenix-hbase-2.2-5.1.2-bin/bin/sqlline.py 192.168.3.151:2181
```
#### 2.执行scheme-hbase.sql的内容
```
复制项目文件scheme-hbase.sql的内容,粘贴到客户端,按键盘的回撤键执行
```
#### 3.由于sql索引数量较大,执行过程大约需要15分钟
```
Exception in thread "SIGWINCH handler" java.lang.RuntimeException: java.sql.SQLFeatureNotSupportedException
```
#### 4.若出现个别如下报错可忽略
```
Exception in thread "SIGWINCH handler" java.lang.RuntimeException: java.sql.SQLFeatureNotSupportedException
```
### 1.8使用dbeaver连接hbase数据库
#### 1.下载dbeaver(23.3.1)
```
我使用的dbeaver-ce-23.3.1-win32.win32.x86_64.zip(23.3.1)版本,可下载最新版本
https://dbeaver.io/download/?spm=a2c6h.12873639.article-detail.6.3abb17b1OGtCqr
```
#### 2.新建Apache Phoenix连接-编辑驱动设置
```
点击插头按钮,新建Apache Phoenix连接
点击下一步
编辑驱动设置
打开'设置'面板
类名:org.apache.phoenix.jdbc.PhoenixDriver
URL模板:jdbc:phoenix:192.168.2.28:2181:/hbase
默认端口:2181
```
#### 3.新建Apache Phoenix连接-库
```
切换到'库'面板
添加依赖文件夹
添加E:\Data\ruoyi-modules-hbase\BOOT-INF\lib目录文件
(lib目录里面的jar包是项目文件中ruoyi-modules-hbase模块maven install打包后生成的jar,进行解压,解压后获取ruoyi-modules-hbase\BOOT-INF\lib中的jar添加dbeaver即可)
```
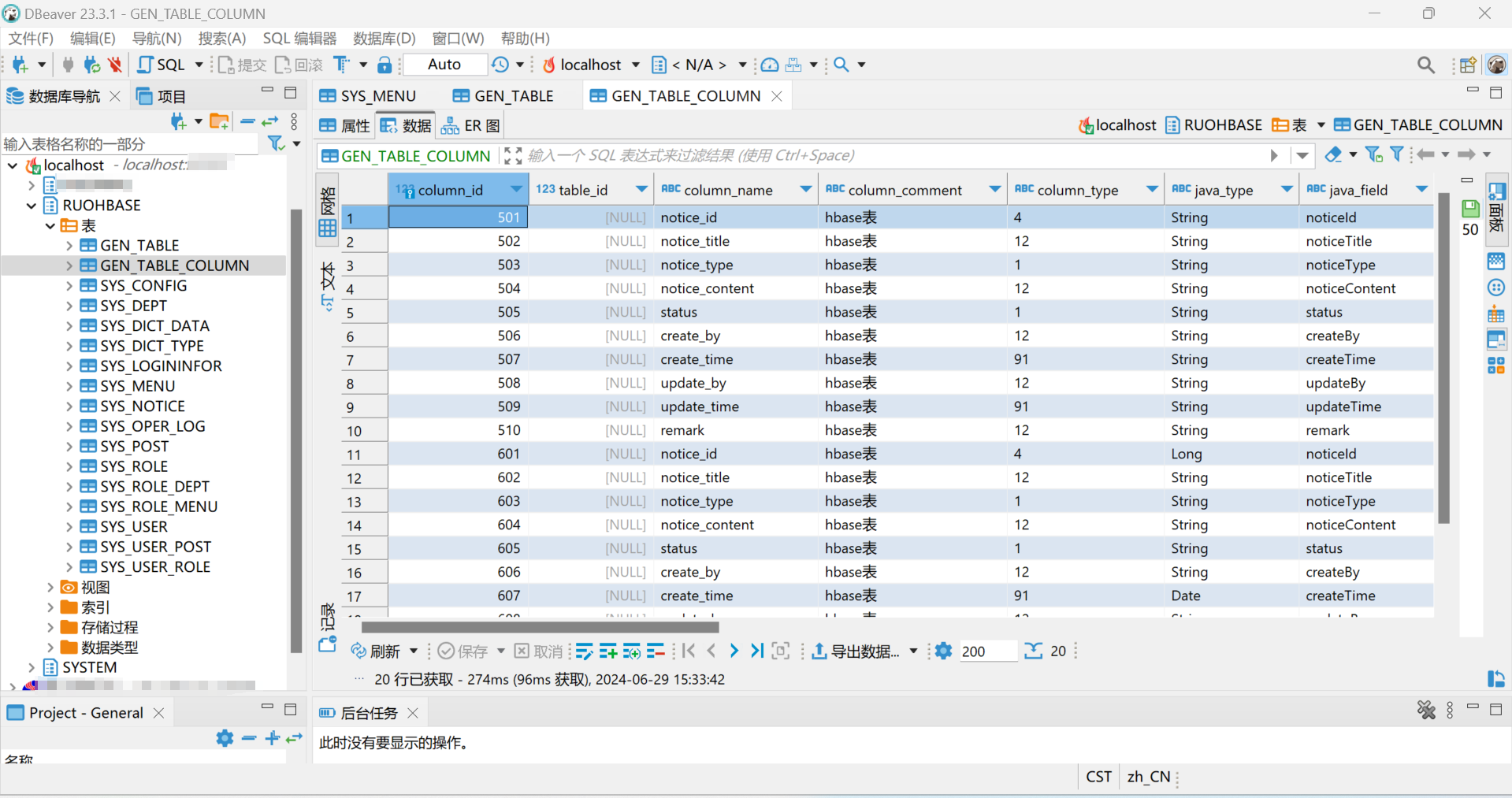
#### 4.出现如下表结构则连接成功