# 爬虫项目4 IP封锁
**Repository Path**: cthousand/item-4
## Basic Information
- **Project Name**: 爬虫项目4 IP封锁
- **Description**: 封IP是一种常见的网站反爬虫策略,其限制了一段时间内某个ip请求的次数,采用代理池技术可以实现每个请求都用不同的IP访问,如何应对IP的不稳定,指定某个请求重试机制,超时机制...
- **Primary Language**: Python
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 1
- **Created**: 2022-04-18
- **Last Updated**: 2023-05-15
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# 项目4.IP封锁
***
## 背景交代
很多网站在爬去了一会数据后会提示IP被封,如下图,
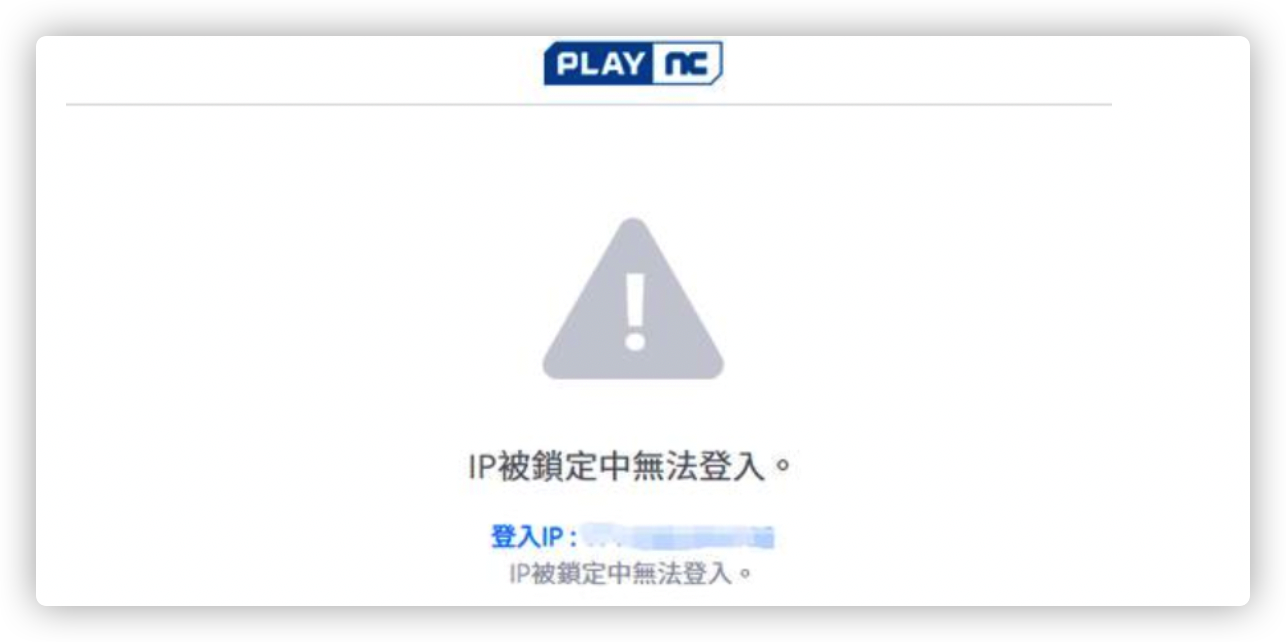 其原理是服务器会检查单位时间内某个IP发起请求的次数,如果超过了设定的阈值,就会阻止该IP的继续接入。
很直接的解决方法是每个请求用不同的IP发起,这个过程叫IP代理。
IP代理有免费和付费两种,网上有很多免费代理,比如快代理网站等,但缺点就是很多人在用,那么如果很多人在同一时间一起用同一个IP发起对某个网站的请求,还是会被封,付费代理由于需要付费,且背后有服务商在持续维护,因此无论是数量还是质量上会更好一些。
目前付费代理主要分为2类:
第一类是提取接口付费代理,其会提供一个api接口,我们可以拿到一个代理列表。
第二类是隧道代理,其会提供一个固定的IP+端口,服务商会在背后分发我们的请求到不同的代理服务器。操作上比第一类要简单。
比较知名的代理商有:快代理,阿布云代理,多倍云代理等。
## 目标明确
网址:https://antispider5.scrape.center/
该网站的特点是单个IP每5分钟最多访问10次,否则会被禁IP,10分钟后解锁。
目标是获取该网站所有电影列表数据,共计要爬10个列表页,和100个详情页。总计请求次数110次。
其原理是服务器会检查单位时间内某个IP发起请求的次数,如果超过了设定的阈值,就会阻止该IP的继续接入。
很直接的解决方法是每个请求用不同的IP发起,这个过程叫IP代理。
IP代理有免费和付费两种,网上有很多免费代理,比如快代理网站等,但缺点就是很多人在用,那么如果很多人在同一时间一起用同一个IP发起对某个网站的请求,还是会被封,付费代理由于需要付费,且背后有服务商在持续维护,因此无论是数量还是质量上会更好一些。
目前付费代理主要分为2类:
第一类是提取接口付费代理,其会提供一个api接口,我们可以拿到一个代理列表。
第二类是隧道代理,其会提供一个固定的IP+端口,服务商会在背后分发我们的请求到不同的代理服务器。操作上比第一类要简单。
比较知名的代理商有:快代理,阿布云代理,多倍云代理等。
## 目标明确
网址:https://antispider5.scrape.center/
该网站的特点是单个IP每5分钟最多访问10次,否则会被禁IP,10分钟后解锁。
目标是获取该网站所有电影列表数据,共计要爬10个列表页,和100个详情页。总计请求次数110次。
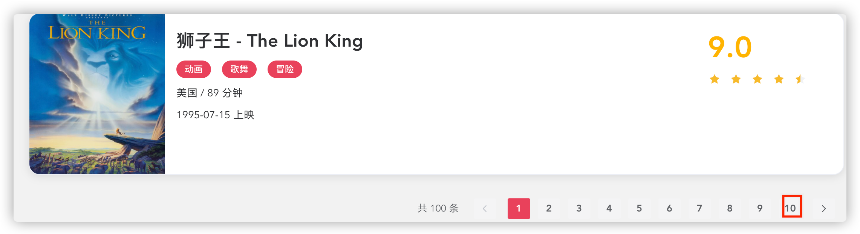 列表页
列表页
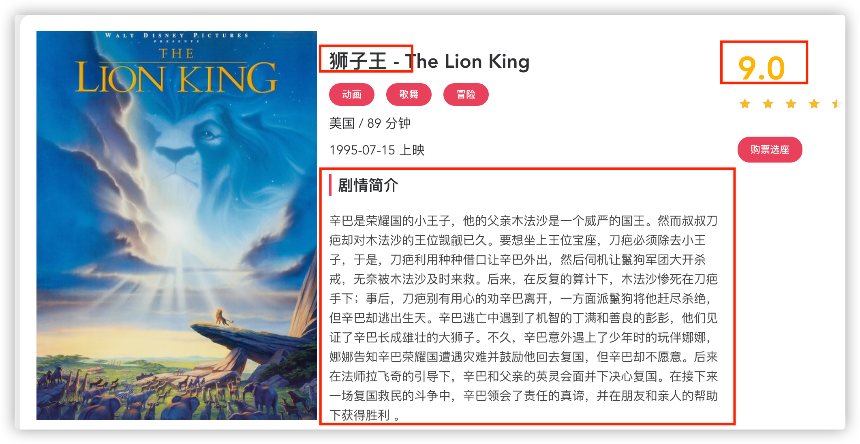 详情页
存储方式采用mysql码,字段采集:标题,评分,简介
## 方法分析
### 付费代理设置
代理商选择快代理(https://www.kuaidaili.com/doc/product/tps/),套餐选择隧道套餐,每次请求都换一次代理。价格方面选择按量计费
详情页
存储方式采用mysql码,字段采集:标题,评分,简介
## 方法分析
### 付费代理设置
代理商选择快代理(https://www.kuaidaili.com/doc/product/tps/),套餐选择隧道套餐,每次请求都换一次代理。价格方面选择按量计费
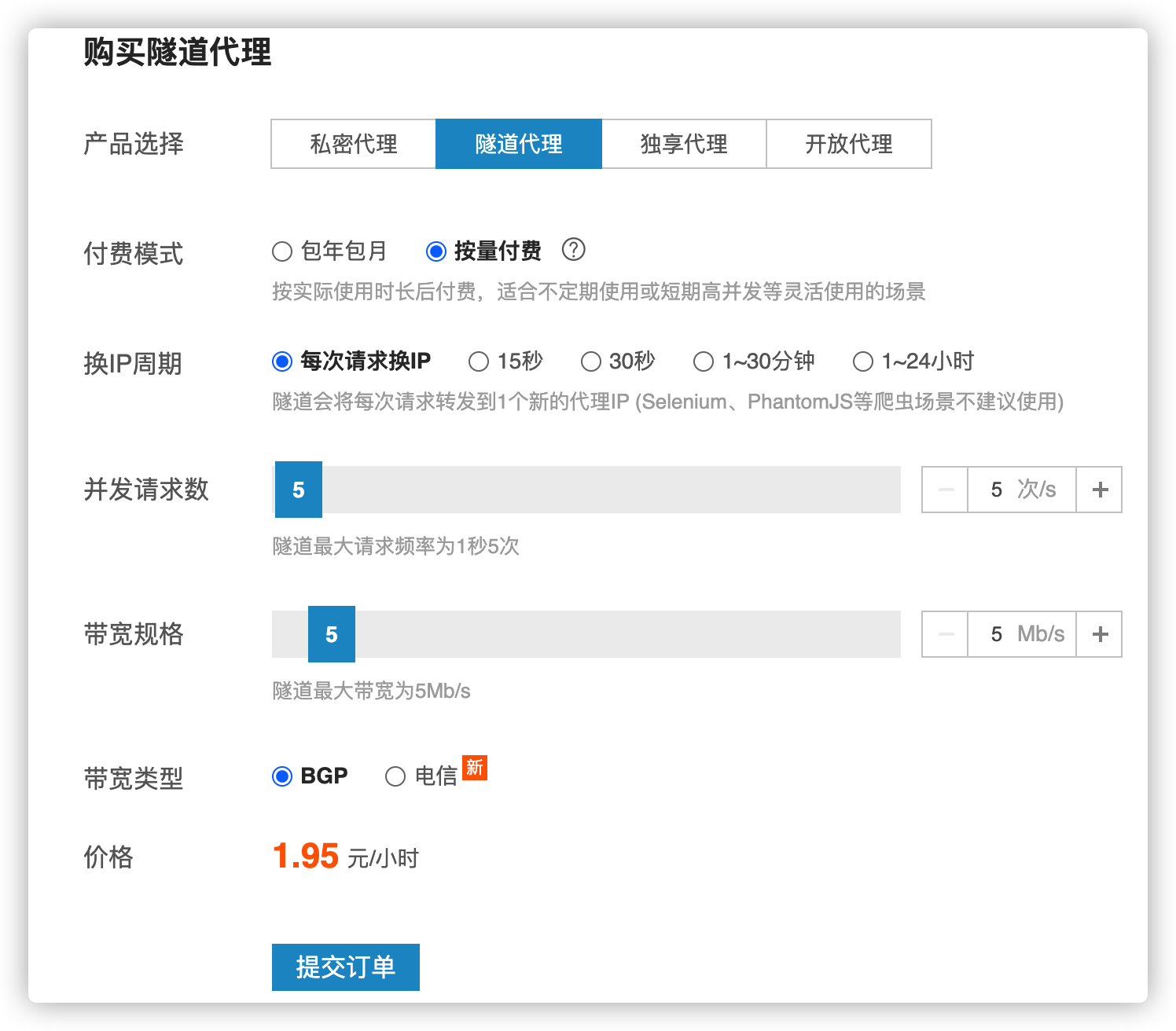 实际计费是按分钟算,结算是没小时结算一次,也就是用几分钟算几分钟。
实际计费是按分钟算,结算是没小时结算一次,也就是用几分钟算几分钟。
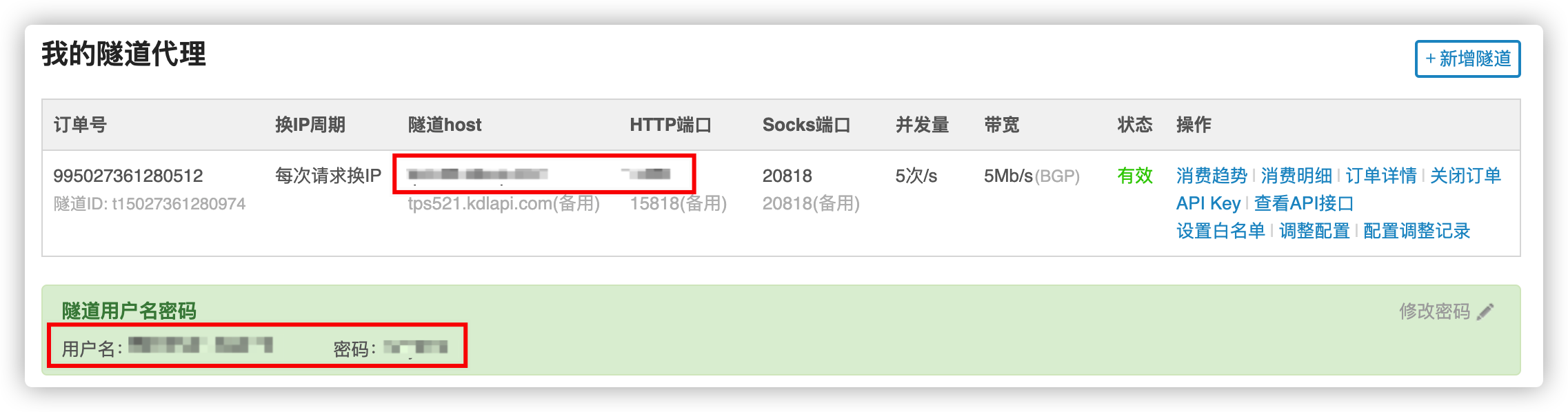 拿到上图图示4个数据,并按照下图配置,之后加入到请求方法中即可
```python
proxy_host = '***'
proxy_port = '***'
proxy_username = '***'
proxy_password = '***'
proxy = f'http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}'
proxies = {
'http': proxy,
'https': proxy
}
```
### 网页分析
1. 开发者工具>network监听>
2. 目标在一个html请求里面,分析网址规律:https://antispider5.scrape.center/page/{page}
3. 点击列表页元素,分析网址规律:https://antispider5.scrape.center/detail/{id}
4. 思路已清晰(本项目主要重点在于IP设置和IP重试)
5. 但及时是付费IP也存在并不稳定的情况,那么我们需要对某个因此失败的请求做重试处理,下面提供2个思路
###常规脚本结构
拿到上图图示4个数据,并按照下图配置,之后加入到请求方法中即可
```python
proxy_host = '***'
proxy_port = '***'
proxy_username = '***'
proxy_password = '***'
proxy = f'http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}'
proxies = {
'http': proxy,
'https': proxy
}
```
### 网页分析
1. 开发者工具>network监听>
2. 目标在一个html请求里面,分析网址规律:https://antispider5.scrape.center/page/{page}
3. 点击列表页元素,分析网址规律:https://antispider5.scrape.center/detail/{id}
4. 思路已清晰(本项目主要重点在于IP设置和IP重试)
5. 但及时是付费IP也存在并不稳定的情况,那么我们需要对某个因此失败的请求做重试处理,下面提供2个思路
###常规脚本结构
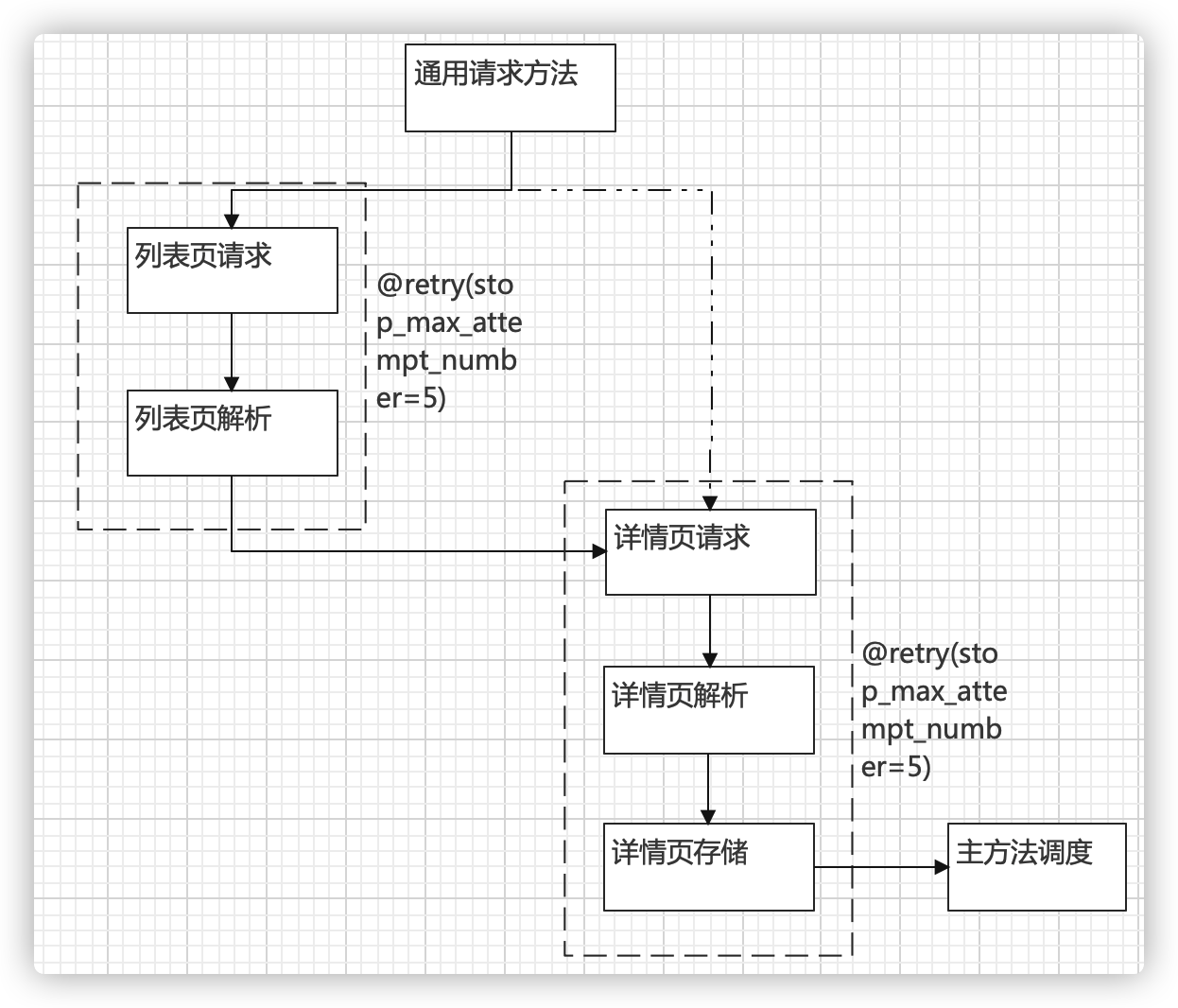 该思路在需要请求的2处各设置一个retry装饰器,并指定最大尝试次数为5次,该装饰器可以理解成
```python
for i in range(5):
try:
xx
except:
xx
```
的简介版本。
### 模块化脚本结构
这样做当然是可行的,但也有自身的局限性,比如,如果跳转的页面很多,那就要设置很多装饰器,所以可以参考scrapy框架的设计理念做如下改动:
该思路在需要请求的2处各设置一个retry装饰器,并指定最大尝试次数为5次,该装饰器可以理解成
```python
for i in range(5):
try:
xx
except:
xx
```
的简介版本。
### 模块化脚本结构
这样做当然是可行的,但也有自身的局限性,比如,如果跳转的页面很多,那就要设置很多装饰器,所以可以参考scrapy框架的设计理念做如下改动:
 scrapy框架图
scrapy框架图
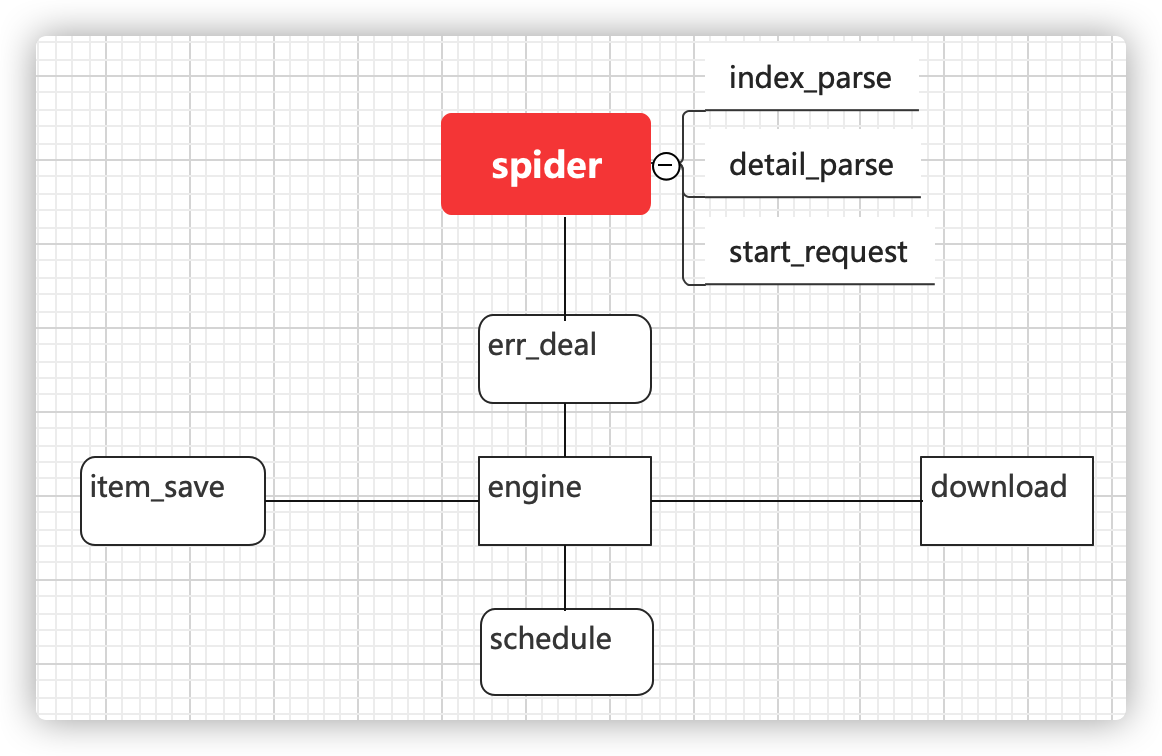 上面这张图可能还是比较抽象,我们来看一个request对象,进入这个结构后,经历了些什么
```python
shedule>download>err_deal
>spider>index_parse>生成request>schedule>...
>detail_parse>生成data>item_save
>shedule
>死亡💀
```
可以容易的发现每个request(此时已经从download处拿到response)在经过err_deal时,会有3条路径,分别是进入spider,进入schedule,和死亡,至于具体走哪一条路,取决于request本身,因次我们有必要让每个request对象都带有一个回调函数,用于决定他在这个路口的下一步走向,那么什么时候加入这个回调函数呢,自然是在request对象生成的时候,这里有2处,一处是start_request,还有一处是index_parse,index_parse之所以没有,是因为我们确定他将只返回数据。
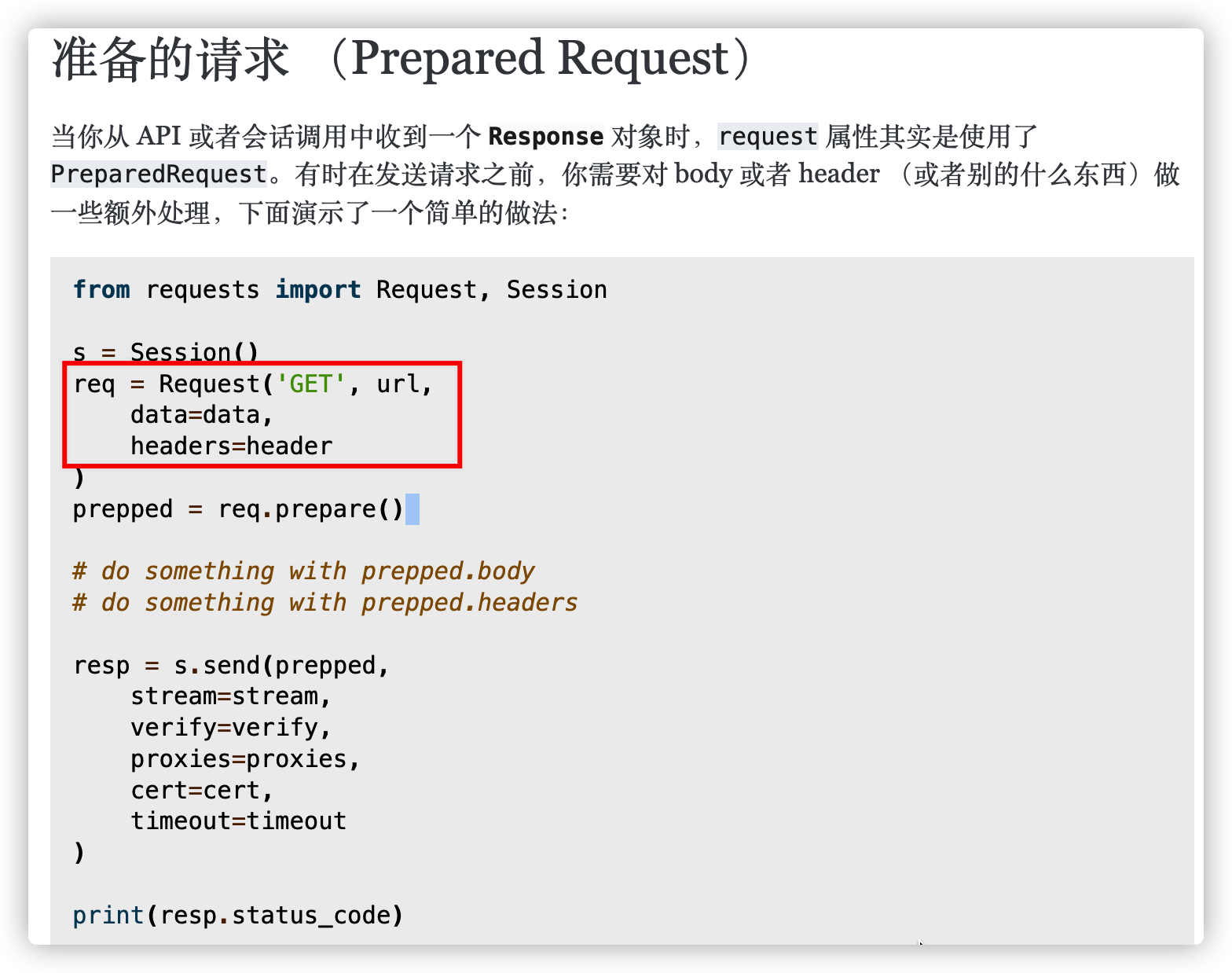
通常我们用requests库的requests方法直接请求网址,但这个方法本身没有callback(回调函数)这个参数,也没有fail_time(失败次数),那么怎么加入这两个参数呢?
查询requests库官方文档可知:(https://docs.python-requests.org/zh_CN/latest/user/advanced.html#prepared-request)
上面这张图可能还是比较抽象,我们来看一个request对象,进入这个结构后,经历了些什么
```python
shedule>download>err_deal
>spider>index_parse>生成request>schedule>...
>detail_parse>生成data>item_save
>shedule
>死亡💀
```
可以容易的发现每个request(此时已经从download处拿到response)在经过err_deal时,会有3条路径,分别是进入spider,进入schedule,和死亡,至于具体走哪一条路,取决于request本身,因次我们有必要让每个request对象都带有一个回调函数,用于决定他在这个路口的下一步走向,那么什么时候加入这个回调函数呢,自然是在request对象生成的时候,这里有2处,一处是start_request,还有一处是index_parse,index_parse之所以没有,是因为我们确定他将只返回数据。
通常我们用requests库的requests方法直接请求网址,但这个方法本身没有callback(回调函数)这个参数,也没有fail_time(失败次数),那么怎么加入这两个参数呢?
查询requests库官方文档可知:(https://docs.python-requests.org/zh_CN/latest/user/advanced.html#prepared-request)
 构建Request对象的子类我们把callback和fail_time(失败次数)这两个参数写入其中。其中设置了超时时间(timeout)为10s,以防有部分请求过于长久。
```python
from requests import Request
class MovieRequest(Request):
# 改写Request类
def __init__(self, callback=None, fail_time=0, timeout=10, method='GET', url=None, headers=None):
Request.__init__(self, method, url, headers)
self.callback = callback
self.fail_time = fail_time
self.timeout = timeout
```
shedule的意思是计划,是用来放置Request请求对象的地方,采用数据库如mysql,自然也是可以的,但没有必要,因为他没有存储的价值,所以我们采用Redis数据库,这个一个基于内存存储的数据库,很适合这种场景。设置如下:
```python
from redis import StrictRedis
from pickle import dumps, loads
from MovieRequest import MovieRequest
class Queto():
# 构建队列类
def __init__(self):
self.db = StrictRedis(host='localhost', port=6379)
def add(self, request):
if isinstance(request, MovieRequest):
return self.db.rpush('antispider', dumps(request))
return False
def pop(self):
if self.db.llen('antispider'):
return loads(self.db.lpop('antispider'))
return False
def empty(self):
return self.db.llen('antispider') == 0
def clear(self):
return self.db.delete('antispider')
```
dumps,loads的作用是将对象序列化和反序列化,因为redis是不接受MovieRequest对象传入的,我们需要用dumps将其转化为字符串存入,loads则将其反转为原对象。
这里首先是实例化了一个StrickRedis类,创建了一个Redis数据库,接着为这个对象配置了4种方法,分别是插入(rpush是增对列表的操作,作用是从右边插入),取出(lpop,表示从列表的左边取出),判空(llen 如果列表的长度为0,那么就是空列表),清除(delete,爬取完成后可以删除这个数据库)
方法分析完毕!接下来就是代码实现了。
## 代码实现
常规脚本结构:ipForbid_retry.py
模块化脚本结构:core包
构建Request对象的子类我们把callback和fail_time(失败次数)这两个参数写入其中。其中设置了超时时间(timeout)为10s,以防有部分请求过于长久。
```python
from requests import Request
class MovieRequest(Request):
# 改写Request类
def __init__(self, callback=None, fail_time=0, timeout=10, method='GET', url=None, headers=None):
Request.__init__(self, method, url, headers)
self.callback = callback
self.fail_time = fail_time
self.timeout = timeout
```
shedule的意思是计划,是用来放置Request请求对象的地方,采用数据库如mysql,自然也是可以的,但没有必要,因为他没有存储的价值,所以我们采用Redis数据库,这个一个基于内存存储的数据库,很适合这种场景。设置如下:
```python
from redis import StrictRedis
from pickle import dumps, loads
from MovieRequest import MovieRequest
class Queto():
# 构建队列类
def __init__(self):
self.db = StrictRedis(host='localhost', port=6379)
def add(self, request):
if isinstance(request, MovieRequest):
return self.db.rpush('antispider', dumps(request))
return False
def pop(self):
if self.db.llen('antispider'):
return loads(self.db.lpop('antispider'))
return False
def empty(self):
return self.db.llen('antispider') == 0
def clear(self):
return self.db.delete('antispider')
```
dumps,loads的作用是将对象序列化和反序列化,因为redis是不接受MovieRequest对象传入的,我们需要用dumps将其转化为字符串存入,loads则将其反转为原对象。
这里首先是实例化了一个StrickRedis类,创建了一个Redis数据库,接着为这个对象配置了4种方法,分别是插入(rpush是增对列表的操作,作用是从右边插入),取出(lpop,表示从列表的左边取出),判空(llen 如果列表的长度为0,那么就是空列表),清除(delete,爬取完成后可以删除这个数据库)
方法分析完毕!接下来就是代码实现了。
## 代码实现
常规脚本结构:ipForbid_retry.py
模块化脚本结构:core包