![]()
💜 Qwen Chat |
🤗 HuggingFace(T2I) |
🤗 HuggingFace(Edit) | 🤖 ModelScope-T2I | 🤖 ModelScope-Edit | 📑 Tech Report | 📑 Blog(T2I) | 📑 Blog(Edit)
🖥️ T2I Demo | 🖥️ Edit Demo | 💬 WeChat (微信) | 🫨 Discord

## Introduction We are thrilled to release **Qwen-Image**, a 20B MMDiT image foundation model that achieves significant advances in **complex text rendering** and **precise image editing**. Experiments show strong general capabilities in both image generation and editing, with exceptional performance in text rendering, especially for Chinese.  ## News - 2025.09.22: This September, we are pleased to introduce Qwen-Image-Edit-2509, the monthly iteration of Qwen-Image-Edit. To experience the latest model, please visit [Qwen Chat](https://qwen.ai) and select the "Image Editing" feature. Compared with Qwen-Image-Edit released in August, the main improvements of Qwen-Image-Edit-2509 include:  - **Multi-image Editing Support**: For multi-image inputs, Qwen-Image-Edit-2509 builds upon the Qwen-Image-Edit architecture and is further trained via image concatenation to enable multi-image editing. It supports various combinations such as "person + person," "person + product," and "person + scene." Optimal performance is currently achieved with 1 to 3 input images. - **Enhanced Single-image Consistency**: For single-image inputs, Qwen-Image-Edit-2509 significantly improves consistency, specifically in the following areas: - **Improved Person Editing Consistency**: Better preservation of facial identity, supporting various portrait styles and pose transformations; - **Improved Product Editing Consistency**: Better preservation of product identity, supporting product poster editing; - **Improved Text Editing Consistency**: In addition to modifying text content, it also supports editing text fonts, colors, and materials; - **Native Support for ControlNet**: Including depth maps, edge maps, keypoint maps, and more. - 2025.08.19: We have observed performance misalignments of Qwen-Image-Edit. To ensure optimal results, please update to the latest diffusers commit. Improvements are expected, especially in identity preservation and instruction following. - 2025.08.18: We’re excited to announce the open-sourcing of Qwen-Image-Edit! 🎉 Try it out in your local environment with the quick start guide below, or head over to [Qwen Chat](https://chat.qwen.ai/) or [Huggingface Demo](https://huggingface.co/spaces/Qwen/Qwen-Image-Edit) to experience the online demo right away! If you enjoy our work, please show your support by giving our repository a star. Your encouragement means a lot to us! - 2025.08.09: Qwen-Image now supports a variety of LoRA models, such as MajicBeauty LoRA, enabling the generation of highly realistic beauty images. Check out the available weights on [ModelScope](https://modelscope.cn/models/merjic/majicbeauty-qwen1/summary).  - 2025.08.05: Qwen-Image is now natively supported in ComfyUI, see [Qwen-Image in ComfyUI: New Era of Text Generation in Images!](https://blog.comfy.org/p/qwen-image-in-comfyui-new-era-of) - 2025.08.05: Qwen-Image is now on Qwen Chat. Click [Qwen Chat](https://chat.qwen.ai/) and choose "Image Generation". - 2025.08.05: We released our [Technical Report](https://arxiv.org/abs/2508.02324) on Arxiv! - 2025.08.04: We released Qwen-Image weights! Check at [Huggingface](https://huggingface.co/Qwen/Qwen-Image) and [ModelScope](https://modelscope.cn/models/Qwen/Qwen-Image)! - 2025.08.04: We released Qwen-Image! Check our [Blog](https://qwenlm.github.io/blog/qwen-image) for more details! > [!NOTE] > Due to heavy traffic, if you'd like to experience our demo online, we also recommend visiting DashScope, WaveSpeed, and LibLib. Please find the links below in the community support. ## Quick Start 1. Make sure your transformers>=4.51.3 (Supporting Qwen2.5-VL) 2. Install the latest version of diffusers ``` pip install git+https://github.com/huggingface/diffusers ``` ### Qwen-Image (for Text-to-Image) The following contains a code snippet illustrating how to use the model to generate images based on text prompts: ```python from diffusers import DiffusionPipeline import torch model_name = "Qwen/Qwen-Image" # Load the pipeline if torch.cuda.is_available(): torch_dtype = torch.bfloat16 device = "cuda" else: torch_dtype = torch.float32 device = "cpu" pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype) pipe = pipe.to(device) positive_magic = { "en": ", Ultra HD, 4K, cinematic composition.", # for english prompt "zh": ", 超清,4K,电影级构图." # for chinese prompt } # Generate image prompt = '''A coffee shop entrance features a chalkboard sign reading "Qwen Coffee 😊 $2 per cup," with a neon light beside it displaying "通义千问". Next to it hangs a poster showing a beautiful Chinese woman, and beneath the poster is written "π≈3.1415926-53589793-23846264-33832795-02384197".''' negative_prompt = " " # Recommended if you don't use a negative prompt. # Generate with different aspect ratios aspect_ratios = { "1:1": (1328, 1328), "16:9": (1664, 928), "9:16": (928, 1664), "4:3": (1472, 1104), "3:4": (1104, 1472), "3:2": (1584, 1056), "2:3": (1056, 1584), } width, height = aspect_ratios["16:9"] image = pipe( prompt=prompt + positive_magic["en"], negative_prompt=negative_prompt, width=width, height=height, num_inference_steps=50, true_cfg_scale=4.0, generator=torch.Generator(device="cuda").manual_seed(42) ).images[0] image.save("example.png") ``` ### Qwen-Image-Edit (for Image Editing, Only Support Single Image Input) > [!NOTE] > Qwen-Image-Edit-2509 has better consistency than Qwen-Image-Edit; it is recommended to use Qwen-Image-Edit-2509 directly,for both single image input and multiple image inputs. ```python import os from PIL import Image import torch from diffusers import QwenImageEditPipeline pipeline = QwenImageEditPipeline.from_pretrained("Qwen/Qwen-Image-Edit") print("pipeline loaded") pipeline.to(torch.bfloat16) pipeline.to("cuda") pipeline.set_progress_bar_config(disable=None) image = Image.open("./input.png").convert("RGB") prompt = "Change the rabbit's color to purple, with a flash light background." inputs = { "image": image, "prompt": prompt, "generator": torch.manual_seed(0), "true_cfg_scale": 4.0, "negative_prompt": " ", "num_inference_steps": 50, } with torch.inference_mode(): output = pipeline(**inputs) output_image = output.images[0] output_image.save("output_image_edit.png") print("image saved at", os.path.abspath("output_image_edit.png")) ``` > [!NOTE] > We have observed that editing results may become unstable if prompt rewriting is not used. Therefore, we strongly recommend applying prompt rewriting to improve the stability of editing tasks. For reference, please see our official [demo script](src/examples/tools/prompt_utils.py) or Advanced Usage below, which includes example system prompts. Qwen-Image-Edit is actively evolving with ongoing development. Stay tuned for future enhancements! ### Qwen-Image-Edit-2509 (for Image Editing, Multiple Image Support and Improved Consistency) ```python import os import torch from PIL import Image from diffusers import QwenImageEditPlusPipeline from io import BytesIO import requests pipeline = QwenImageEditPlusPipeline.from_pretrained("Qwen/Qwen-Image-Edit-2509", torch_dtype=torch.bfloat16) print("pipeline loaded") pipeline.to('cuda') pipeline.set_progress_bar_config(disable=None) image1 = Image.open(BytesIO(requests.get("https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/edit2509/edit2509_1.jpg").content)) image2 = Image.open(BytesIO(requests.get("https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/edit2509/edit2509_2.jpg").content)) prompt = "The magician bear is on the left, the alchemist bear is on the right, facing each other in the central park square." inputs = { "image": [image1, image2], "prompt": prompt, "generator": torch.manual_seed(0), "true_cfg_scale": 4.0, "negative_prompt": " ", "num_inference_steps": 40, "guidance_scale": 1.0, "num_images_per_prompt": 1, } with torch.inference_mode(): output = pipeline(**inputs) output_image = output.images[0] output_image.save("output_image_edit_plus.png") print("image saved at", os.path.abspath("output_image_edit_plus.png")) ``` ### Advanced Usage #### Prompt Enhance for Text-to-Image For enhanced prompt optimization and multi-language support, we recommend using our official Prompt Enhancement Tool powered by Qwen-Plus . You can integrate it directly into your code: ```python from tools.prompt_utils import rewrite prompt = rewrite(prompt) ``` Alternatively, run the example script from the command line: ```bash cd src DASHSCOPE_API_KEY=sk-xxxxxxxxxxxxxxxxxxxx python examples/generate_w_prompt_enhance.py ``` #### Prompt Enhance for Image Edit For enhanced stability, we recommend using our official Prompt Enhancement Tool powered by Qwen-VL-Max. You can integrate it directly into your code: ```python from tools.prompt_utils import polish_edit_prompt prompt = polish_edit_prompt(prompt, pil_image) ``` ## Deploy Qwen-Image Qwen-Image supports Multi-GPU API Server for local deployment: ### Multi-GPU API Server Pipeline & Usage The Multi-GPU API Server will start a Gradio-based web interface with: - Multi-GPU parallel processing - Queue management for high concurrency - Automatic prompt optimization - Support for multiple aspect ratios Configuration via environment variables: ```bash export NUM_GPUS_TO_USE=4 # Number of GPUs to use export TASK_QUEUE_SIZE=100 # Task queue size export TASK_TIMEOUT=300 # Task timeout in seconds ``` ```bash # Start the gradio demo server, api key for prompt enhance cd src DASHSCOPE_API_KEY=sk-xxxxxxxxxxxxxxxxx python examples/demo.py ``` ## Showcase For previous showcases, click the following links: - [Qwen-Image](./Qwen-Image.md) - [Qwen-Image-Edit](./Qwen-Image.md) ### Showcase of Qwen-Image Edit-2509 **The primary update in Qwen-Image-Edit-2509 is support for multi-image inputs.** Let’s first look at a "person + person" example:  Here is a "person + scene" example:  Below is a "person + object" example:  In fact, multi-image input also supports commonly used ControlNet keypoint maps—for example, changing a person’s pose:  Similarly, the following examples demonstrate results using three input images:    --- **Another major update in Qwen-Image-Edit-2509 is enhanced consistency.** First, regarding person consistency, Qwen-Image-Edit-2509 shows significant improvement over Qwen-Image-Edit. Below are examples generating various portrait styles:  For instance, changing a person’s pose while maintaining excellent identity consistency:  Leveraging this improvement along with Qwen-Image’s unique text rendering capability, we find that Qwen-Image-Edit-2509 excels at creating meme images:  Of course, even with longer text, Qwen-Image-Edit-2509 can still render it while preserving the person’s identity:  Person consistency is also evident in old photo restoration. Below are two examples:  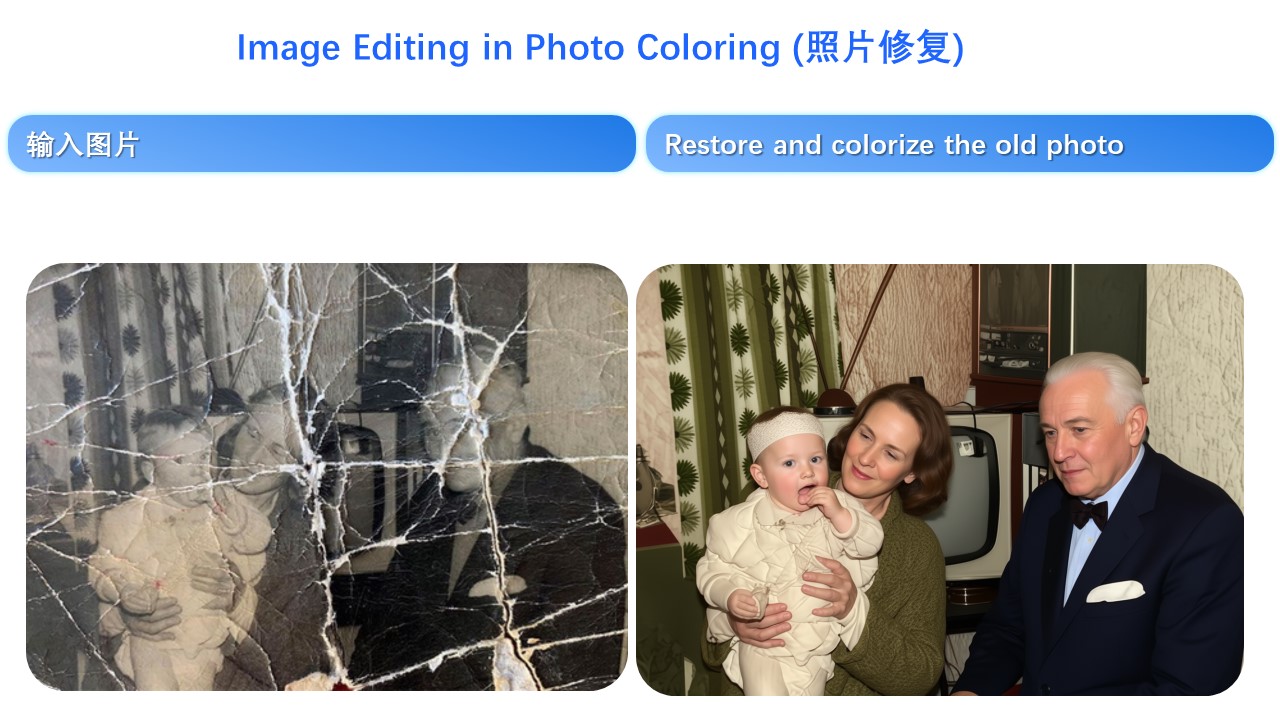 Naturally, besides real people, generating cartoon characters and cultural creations is also possible:  Second, Qwen-Image-Edit-2509 specifically enhances product consistency. We find that the model can naturally generate product posters from plain-background product images:  Or even simple logos:  Third, Qwen-Image-Edit-2509 specifically enhances text consistency and supports editing font type, font color, and font material:    Moreover, the ability for precise text editing has been significantly enhanced:   It is worth noting that text editing can often be seamlessly integrated with image editing—for example, in this poster editing case:  --- **The final update in Qwen-Image-Edit-2509 is native support for commonly used ControlNet image conditions, such as keypoint control and sketches:**    --- The above summarizes the main enhancements in this update. We hope you enjoy using Qwen-Image-Edit-2509! ## AI Arena To comprehensively evaluate the general image generation capabilities of Qwen-Image and objectively compare it with state-of-the-art closed-source APIs, we introduce [AI Arena](https://aiarena.alibaba-inc.com), an open benchmarking platform built on the Elo rating system. AI Arena provides a fair, transparent, and dynamic environment for model evaluation. In each round, two images—generated by randomly selected models from the same prompt—are anonymously presented to users for pairwise comparison. Users vote for the better image, and the results are used to update both personal and global leaderboards via the Elo algorithm, enabling developers, researchers, and the public to assess model performance in a robust and data-driven way. AI Arena is now publicly available, welcoming everyone to participate in model evaluations.  The latest leaderboard rankings can be viewed at [AI Arena Learboard](https://aiarena.alibaba-inc.com/corpora/arena/leaderboard?arenaType=text2image). If you wish to deploy your model on AI Arena and participate in the evaluation, please contact weiyue.wy@alibaba-inc.com. ## Community Support ### Huggingface Diffusers has supported Qwen-Image since day 0. Support for LoRA and finetuning workflows is currently in development and will be available soon. ### ModelScope * **[DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio)** provides comprehensive support for Qwen-Image, including low-GPU-memory layer-by-layer offload (inference within 4GB VRAM), FP8 quantization, LoRA / full training. * **[DiffSynth-Engine](https://github.com/modelscope/DiffSynth-Engine)** delivers advanced optimizations for Qwen-Image inference and deployment, including FBCache-based acceleration, classifier-free guidance (CFG) parallel, and more. * **[ModelScope AIGC Central](https://www.modelscope.cn/aigc)** provides hands-on experiences on Qwen Image, including: - [Image Generation](https://www.modelscope.cn/aigc/imageGeneration): Generate high fidelity images using the Qwen Image model. - [LoRA Training](https://www.modelscope.cn/aigc/modelTraining): Easily train Qwen Image LoRAs for personalized concepts. ### WaveSpeedAI WaveSpeed has deployed Qwen-Image on their platform from day 0, visit their [model page](https://wavespeed.ai/models/wavespeed-ai/qwen-image/text-to-image) for more details. ### LiblibAI LiblibAI offers native support for Qwen-Image from day 0. Visit their [community](https://www.liblib.art/modelinfo/c62a103bd98a4246a2334e2d952f7b21?from=sd&versionUuid=75e0be0c93b34dd8baeec9c968013e0c) page for more details and discussions. ### Inference Acceleration Method: cache-dit cache-dit offers cache acceleration support for Qwen-Image with DBCache, TaylorSeer and Cache CFG. Visit their [example](https://github.com/vipshop/cache-dit/blob/main/examples/pipeline/run_qwen_image.py) for more details. ## License Agreement Qwen-Image is licensed under Apache 2.0. ## Citation We kindly encourage citation of our work if you find it useful. ```bibtex @misc{wu2025qwenimagetechnicalreport, title={Qwen-Image Technical Report}, author={Chenfei Wu and Jiahao Li and Jingren Zhou and Junyang Lin and Kaiyuan Gao and Kun Yan and Sheng-ming Yin and Shuai Bai and Xiao Xu and Yilei Chen and Yuxiang Chen and Zecheng Tang and Zekai Zhang and Zhengyi Wang and An Yang and Bowen Yu and Chen Cheng and Dayiheng Liu and Deqing Li and Hang Zhang and Hao Meng and Hu Wei and Jingyuan Ni and Kai Chen and Kuan Cao and Liang Peng and Lin Qu and Minggang Wu and Peng Wang and Shuting Yu and Tingkun Wen and Wensen Feng and Xiaoxiao Xu and Yi Wang and Yichang Zhang and Yongqiang Zhu and Yujia Wu and Yuxuan Cai and Zenan Liu}, year={2025}, eprint={2508.02324}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2508.02324}, } ``` ## Contact and Join Us If you'd like to get in touch with our research team, we'd love to hear from you! Join our [Discord](https://discord.gg/z3GAxXZ9Ce) or scan the QR code to connect via our [WeChat groups](assets/wechat.png) — we're always open to discussion and collaboration. If you have questions about this repository, feedback to share, or want to contribute directly, we welcome your issues and pull requests on GitHub. Your contributions help make Qwen-Image better for everyone. If you're passionate about fundamental research, we're hiring full-time employees (FTEs) and research interns. Don't wait — reach out to us at fulai.hr@alibaba-inc.com ## Star History [](https://www.star-history.com/#QwenLM/Qwen-Image&Date)
{kind=link}